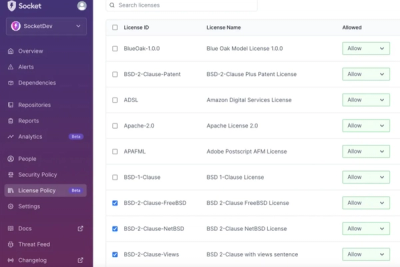
Product
Introducing License Enforcement in Socket
Ensure open-source compliance with Socket’s License Enforcement Beta. Set up your License Policy and secure your software!
By Philipp Burckhardt - Oct 17, 2024
remark-parse
Advanced tools
The remark-parse package is a plugin for the Remark processor that parses Markdown content into a syntax tree. It is part of the unified ecosystem, which provides a way to parse, transform, and stringify content using abstract syntax trees (ASTs).
Parsing Markdown
This feature allows you to parse Markdown content and transform it into an abstract syntax tree (AST). The code sample demonstrates how to use remark-parse with the remark library to parse a simple Markdown string.
const remark = require('remark');
const parse = require('remark-parse');
remark().use(parse).process('# Hello world!', function(err, file) {
if (err) throw err;
console.log(file);
});Extensible Markdown Parsing
remark-parse can be extended with plugins to handle custom Markdown syntax. In this example, the 'remark-math' plugin is used to parse mathematical expressions within the Markdown content.
const remark = require('remark');
const parse = require('remark-parse');
const math = require('remark-math');
remark().use(parse).use(math).process('Euler's identity: $e^{i\pi} + 1 = 0$', function(err, file) {
if (err) throw err;
console.log(file);
});markdown-it is a Markdown parser with a similar goal to remark-parse, but it is implemented differently. It is often used for its speed and extensibility with plugins, and it can output HTML directly instead of an AST.
marked is another Markdown parser that is known for being fast and lightweight. It is less extensible than remark-parse but can be a good choice for simpler use cases where a full AST is not required.




![]()
![]()
![]()
Parser for unified. Parses Markdown to mdast syntax trees. Used in the remark processor but can be used on its own as well. Can be extended to change how markdown is parsed.

🥇 ZEIT |

🥇 Gatsby |

🥇 Netlify |

Holloway |
You? |
Read more about the unified collective on Medium »
npm:
npm install remark-parse
var unified = require('unified')
var createStream = require('unified-stream')
var markdown = require('remark-parse')
var remark2rehype = require('remark-rehype')
var html = require('rehype-stringify')
var processor = unified()
.use(markdown, {commonmark: true})
.use(remark2rehype)
.use(html)
process.stdin.pipe(createStream(processor)).pipe(process.stdout)
See unified for more examples »
processor().use(parse[, options])Configure the processor to read Markdown as input and process
mdast syntax trees.
optionsOptions can be passed directly, or passed later through
processor.data().
options.gfmGFM mode (boolean, default: true).
hello ~~hi~~ world
Turns on:
options.commonmarkCommonMark mode (boolean, default: false).
This is a paragraph
and this is also part of the preceding paragraph.
Allows:
( and )) around link and image titles)) as an ordered list markerDisallows:
# Hash headings) without spacing after opening hashes or and
before closing hashesUnderline headings\n---) when following a paragraph< and
>)>), for lists, code, and thematic breaksoptions.footnotesFootnotes mode (boolean, default: false).
Something something[^or something?].
And something else[^1].
[^1]: This reference footnote contains a paragraph...
* ...and a list
Enables reference footnotes and inline footnotes.
Both are wrapped in square brackets and preceded by a caret (^), and can be
referenced from inside other footnotes.
options.pedanticPedantic mode (boolean, default: false).
Check out some_file_name.txt
Turns on:
_alpha_) and importance (__bravo__) with underscores in words*, -, +)commonmark is also turned on, ordered lists with different markers
(., ))options.blocksBlocks (Array.<string>, default: list of block HTML elements).
<block>foo
</block>
Defines which HTML elements are seen as block level.
parse.ParserAccess to the parser, if you need it.
Typically, using transformers to manipulate a syntax tree produces the desired output. Sometimes, such as when introducing new syntactic entities with a certain precedence, interfacing with the parser is necessary.
If the remark-parse plugin is used, it adds a Parser constructor
function to the processor.
Other plugins can add tokenizers to its prototype to change how Markdown is
parsed.
The below plugin adds a tokenizer for at-mentions.
module.exports = mentions
function mentions() {
var Parser = this.Parser
var tokenizers = Parser.prototype.inlineTokenizers
var methods = Parser.prototype.inlineMethods
// Add an inline tokenizer (defined in the following example).
tokenizers.mention = tokenizeMention
// Run it just before `text`.
methods.splice(methods.indexOf('text'), 0, 'mention')
}
Parser#blockTokenizersMap of names to tokenizers (Object.<Function>).
These tokenizers (such as fencedCode, table, and paragraph) eat from the
start of a value to a line ending.
See #blockMethods below for a list of methods that are included by default.
Parser#blockMethodsList of blockTokenizers names (Array.<string>).
Specifies the order in which tokenizers run.
Precedence of default block methods is as follows:
newlineindentedCodefencedCodeblockquoteatxHeadingthematicBreaklistsetextHeadinghtmlfootnotedefinitiontableparagraphParser#inlineTokenizersMap of names to tokenizers (Object.<Function>).
These tokenizers (such as url, reference, and emphasis) eat from the start
of a value.
To increase performance, they depend on locators.
See #inlineMethods below for a list of methods that are included by default.
Parser#inlineMethodsList of inlineTokenizers names (Array.<string>).
Specifies the order in which tokenizers run.
Precedence of default inline methods is as follows:
escapeautoLinkurlhtmllinkreferencestrongemphasisdeletioncodebreaktextfunction tokenizer(eat, value, silent)There are two types of tokenizers: block level and inline level. Both are functions, and work the same, but inline tokenizers must have a locator.
The following example shows an inline tokenizer that is added by the mentions plugin above.
tokenizeMention.notInLink = true
tokenizeMention.locator = locateMention
function tokenizeMention(eat, value, silent) {
var match = /^@(\w+)/.exec(value)
if (match) {
if (silent) {
return true
}
return eat(match[0])({
type: 'link',
url: 'https://social-network/' + match[1],
children: [{type: 'text', value: match[0]}]
})
}
}
Tokenizers test whether a document starts with a certain syntactic entity. In silent mode, they return whether that test passes. In normal mode, they consume that token, a process which is called “eating”.
Locators enable inline tokenizers to function faster by providing where the next entity may occur.
Node? = tokenizer(eat, value)boolean? = tokenizer(eat, value, silent)eat (Function) — Eat, when applicable, an entityvalue (string) — Value which may start an entitysilent (boolean, optional) — Whether to detect or consumelocator (Function) — Required for inline tokenizersonlyAtStart (boolean) — Whether nodes can only be found at the beginning
of the documentnotInBlock (boolean) — Whether nodes cannot be in blockquotes, lists, or
footnote definitionsnotInList (boolean) — Whether nodes cannot be in listsnotInLink (boolean) — Whether nodes cannot be in linksboolean?, in silent mode — whether a node can be found at the start of
valueNode?, In normal mode — If it can be found at the start of
valuetokenizer.locator(value, fromIndex)Locators are required for inline tokenizers. Their role is to keep parsing performant.
The following example shows a locator that is added by the mentions tokenizer above.
function locateMention(value, fromIndex) {
return value.indexOf('@', fromIndex)
}
Locators enable inline tokenizers to function faster by providing information on where the next entity may occur. Locators may be wrong, it’s OK if there actually isn’t a node to be found at the index they return.
value (string) — Value which may contain an entityfromIndex (number) — Position to start searching atnumber — Index at which an entity may start, and -1 otherwise.
eat(subvalue)var add = eat('foo')
Eat subvalue, which is a string at the start of the tokenized
value.
subvalue (string) - Value to eatadd.
add(node[, parent])var add = eat('foo')
add({type: 'text', value: 'foo'})
Add positional information to node and add node to parent.
node (Node) - Node to patch position on and to addparent (Parent, optional) - Place to add node to in the
syntax tree.
Defaults to the currently processed nodeNode — The given node.
add.test()Get the positional information that would be patched on node by
add.
add.reset(node[, parent])add, but resets the internal position.
Useful for example in lists, where the same content is first eaten for a list,
and later for list items.
node (Node) - Node to patch position on and insertparent (Node, optional) - Place to add node to in
the syntax tree.
Defaults to the currently processed nodeNode — The given node.
In some situations, you may want to turn off a tokenizer to avoid parsing that syntactic feature.
Preferably, use the remark-disable-tokenizers
plugin to turn off tokenizers.
Alternatively, this can be done by replacing the tokenizer from
blockTokenizers (or blockMethods) or inlineTokenizers (or
inlineMethods).
The following example turns off indented code blocks:
remarkParse.Parser.prototype.blockTokenizers.indentedCode = indentedCode
function indentedCode() {
return true
}
As Markdown is sometimes used for HTML, and improper use of HTML can open you up
to a cross-site scripting (XSS) attack, use of remark can also be unsafe.
When going to HTML, use remark in combination with the rehype
ecosystem, and use rehype-sanitize to make the tree safe.
Use of remark plugins could also open you up to other attacks. Carefully assess each plugin and the risks involved in using them.
See contributing.md in remarkjs/.github for ways
to get started.
See support.md for ways to get help.
Ideas for new plugins and tools can be posted in remarkjs/ideas.
A curated list of awesome remark resources can be found in awesome remark.
This project has a Code of Conduct. By interacting with this repository, organisation, or community you agree to abide by its terms.
FAQs
remark plugin to add support for parsing markdown input
We found that remark-parse demonstrated a not healthy version release cadence and project activity because the last version was released a year ago. It has 2 open source maintainers collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Ensure open-source compliance with Socket’s License Enforcement Beta. Set up your License Policy and secure your software!
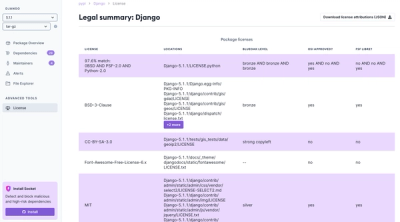
Product
We're launching a new set of license analysis and compliance features for analyzing, managing, and complying with licenses across a range of supported languages and ecosystems.
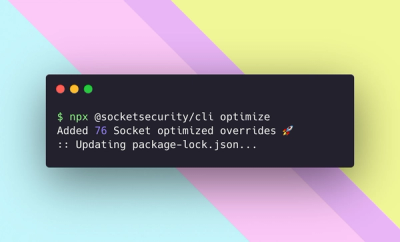
Product
We're excited to introduce Socket Optimize, a powerful CLI command to secure open source dependencies with tested, optimized package overrides.